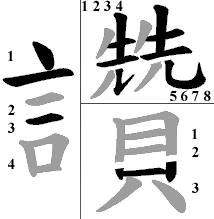
.....分頁模式 ......倉頡取碼原則(綱要) .......例外字 ........常用單字 .........練習 一|二|三|四|五|六|七|八|九|十 (一)中文字:最少1碼,最多5碼 使用「倉頡輸入法」輸入中文字,每次取碼不能多過5個。 例: 倉 OIAR <取碼「數目」正確> 頡 GRMBUC <不對,多過5個碼> (二)「字首」最多2碼,「字身」最多3碼 倉頡輸入法將所有「中文字」分為「連體字」和「分體字」。 如果一個中文字可以分為兩個或以上的部份,它便是「分體字」。 例: 如果一個中文字不可以被分割,它便是「連體字」。 例: 無法分割 只有分體字才有「字首」和「字身」--「分體字」被分割後,第一個被分出來部份便是「字首」,其餘的全是「字身」。 例: 「水」 字首(第一個被分出來的部份) 「青」 字身(餘下的部份) 「耳口」字首(第一個被分出來的部份) 「壬」 字身(餘下的部份) (三)連體字:最多4碼(1-4碼) 頭、2、3、尾 以倉頡輸入法輸入中文字最多可取5個碼,然而,如果那個字是「連體字」的話,則最多只可以取4個碼。 因此,遇到由五個或以上的字形組成的「連體字」,我們只會取「頭、2、3、尾」共四個碼--就是第一個、第二個、第三個和最後一個字形。 例: 「為」字由 I、K、N、N、S、F 六個字形組成,但我們只取「頭、2、3、尾」四個碼: I、K、N、N、S、F 因此,「為」字的倉頡碼便是:IKNF 「業」字由 T、C、T、J、D 五個字形組成,但我們只取「頭、2、3、尾」4個碼: T、C、T、J、D 因此,「業」字的倉頡碼便是:TCTD (四)分體字:最多5碼(2-5碼) A型 頭、尾; 頭、2、尾 (字 首) (字 身) B型 頭、尾; 頭、尾; 尾 (字 首) (字身第一部) (字身第二部) 分體字由兩個或以上的部份組成,因此最少有2個倉頡碼。 我們已在前面提過,分體字的「字首」最多可有2個碼,分體字的「字身」最多可有3個碼,所以其實只有「分體字」才可能有5個碼。 「字首」最多可有2個碼,因此,遇到由兩個以上的字形組成的「字首」,我們只會取「頭、尾」共2個碼--就是第一個和最後一個字形。 「字身」最多可有3個碼,因此,遇到由三個以上的字形組成的「字身」,我們只會取「頭、2、尾」共3個碼--就是第一個、第二個和第三個字形。 所以,我們說「分體字」取「頭、尾;頭、2、尾」。 例: 「靚」字由「青」、「見」兩部份組成,「青」是「字首」,「見」是「字身」。 「青」字由 Q、M、B 三個字形組成,但我們只取「頭、尾」2個碼: Q、M、B 「見」字由 B、U、H、U 四個字形組成,但我們只取「頭、2、尾」3個碼: B、U、H、U 因此,「靚」字的倉頡碼便是:QB-BUU。* * * 「字首」和「字身」互不讓碼--「字首」碼數限額為2個,「字身」碼數限額為3個,有時「字首」用不著2個碼,而字身則配額不足,不能全取所有字形。 在這情況下,「字首」仍不會讓碼給「字身」。 例: 「偽」字的「字首」是 O,「字身」是 I、K、N、N、S、F。雖然「字首」只得1個碼,「字首」卻不會將餘下的配額讓給「字身」。 所以,按著「頭、尾;頭、2、尾」的取碼方法,取 O-IKF。 O - I、K、N、N、S、F 相反,有時「字身」用不著3個碼,而字首則配額不足,不能全取所有字形。 在這情況下,「字身」也不會讓碼給「字首」。 例: 「熱」字的「字首」是 G、C、G、K、N、I,「字身」是 F。雖然「字身」只得1個碼,「字身」卻不會將餘下的配額讓給「字首」。 所以,按著「頭、尾;頭、2、尾」的取碼方法,取 GI-F。 G、C、G、K、N、I - F* * * 為求取碼更方便,我們再將「分體字」細分為A型和B型。 A型「分體字」字身不可被分割,如上述「靚」字、「偽」字等。 按著「頭、尾;頭、2、尾」的方法取碼--字首取「頭、尾」,字身取「頭、2、尾」。 B型「分體字」字身可以被分割,如「讚」字。 按著「頭、尾;頭、尾;尾」的方法取碼--字首取「頭、尾」,字身第一部份取「頭、尾」,字身第二部份取「尾」。 例: 「讚」字屬於B型「分體字」,字首是「言」,字身第一部份是「先先」,第二部份是「貝」。 字首「言」字由 Y、M、M、R 組成,只取「頭、尾」碼: Y、M、M、R 字身第一部份「先先」由 H、G、H、U、H、G、H、U 組成,只取「頭、尾」碼: H、G、H、U、H、G、H、U 字身第二部份「貝」由 B、U、C 組成,只取「尾」碼: B、U、C 因此,「讚」字的倉頡碼便是:YR-HUC * * * 需額外處理的B型「分體字」: 如果一個B型「分體字」的「字身第一部份」只有一個碼,我們便需要留意。 以「條」字為例,若以B型的取碼方法「頭、尾;頭、尾;尾」取碼(O-L-D),「條」字的字身便只得2個碼。然而,「條」字的字身是由3個以上的字型組成的(L、O、K、D),在字身最多可有3個碼的前題下,這種方法致令「條」字的字身少了一個碼。 (註:所謂「分體字A型」及「分體字B型」的分野,其實並不存在,這種分法是為取碼時更方便而設。) 遇上這種情況,我們可以乾脆將那個字當作「分體字A型」取碼。 例: (錯) 「頭、尾; 頭、尾; 尾」 O - L - OKD O-L-D (對) 「頭、尾; 頭、2、尾」 O - LOKD O-LOD(或作O-L-OD) (錯) 「頭、尾; 頭、尾; 尾」 HO - C - MMN HO-C-N (對) 「頭、尾; 頭、2、尾」 HO - CMMN HO-CMN(或作HO-C-MN) (五)取碼順序方向∼上至下;左至右;外至內 取碼時依循 由上至下 由左至右 由外至內 的方向,順序取碼。 以分劃字首、字身的角度來說,上面的是字首,下面的是字身; 左面的是字首,右面的是字身; 外面的是字首,裡面的是字身。 初學者必須緊記:倉頡輸入法並非按「筆劃」次序取碼,而是按著「位置」、依循上述的方向順序取字形。不過,「筆劃」偶然也會對取碼有幫助,因為我們平日寫字大多是按著上至下、左至右、外至內的方法寫的,有時卻完全不對。 例: 「式」字--按筆劃,是PMI;按上至下的原則,是IPM。後者才是正確的。 另一點需要留意的是:「尾」碼是指最後一個碼,而不是指最貼近底線的碼。 例: 「貓」字的字首是 BH 而不是 BS ,雖然 S 比 H 貼近底線,但按著上至下的次序,S 的上方比兩個 H 都高,所以 S 排序較先,並非「尾」碼。 (六)精簡原則 「精簡原則」就是說我們取碼時務必盡量精簡,碼數愈少愈好。 例: 「口」字是字首 R;所以「品」字的倉頡碼是 RRR。 我們斷不會將「口」字拆開變成三3個或4個字形,否則,「品」字便會變成由9至12個字形合成的字了。 (錯) 某些字有「儿」(HU)這部份,如:「見」(BUHU) 某些字有「儿」(HU)這部份,如:「先」(HGHU) 某些字有「儿」(HU)這部份,如:「兒」(HXHU) 但外型相近的「元」字和「光」字卻不大相同。我們或會以為「元」是 MMHU;「光」是 FMHU,其實不然,「元」應該是 MMU;而「光」應該是 FMU。 「元」字的第二個字型「M」,不是「一劃」,而是「一劃一撇」(如圖所示)。由於 MMU 的組合比 MMHU 精簡,所以選擇前者。 「光」字的第二個字型「M」,也不是「一劃」,而是「一劃一撇」(如圖所示)。由於FMU的組合比FMHU精簡,所以選擇前者。 此外,很多初學者都不明白為何「非」字的字身取「YYY」,而不取「LMM」,其實也是同樣的原理。如果「非」字的字身取「LMM」,那不就是說該字的字身是由「LMMM」組成?「LMMM」和「YYY」相比,多了一個碼,因此,「YYY」比較精簡。 (錯)LM-LMM 源自「LMMM-LMMM」拆法,共8個字型。 (對)LM-YYY 源自「LMMM-YYY」拆法,共7個字型。 (七)完整原則:按序取碼,每次盡量多取 「完整原則」是指每次取碼時,均盡可能多取多要。 例: 按著上述的原理,「夫」字應該是 QO,而不是 JK。 雖然兩者均只取2碼(兩者皆合乎精簡原則),但取「Q」比取「J」所取部份更多,所以選擇先取「Q」。 (對) (錯)取「J」不及取「Q」多 (錯)不精簡,共4個碼。 同一原理,雖然「家」字和「象」字的下半部看來很似,但兩字的取碼方法不同。 「家」字是 J-MSO;「象」字則是 NAPO。 「家」字的第二個字型「M」,和「元」字的第二個字型一樣,是「一劃一撇」(如圖所示),因為取「一劃一撇」比單取「一劃」多,餘下的字型(第三個字型)缺了一撇,變成「S」。 相反,「象」字的第三個字型沒有被取去一撇,所以是「P」。 現在請大家想想:「難」字的字首是甚麼? 很多同學都會以為「難」字的字首是「TK」。我們知道字首是取「頭、尾」2碼的:看看字首的上面,再看看字首的下面,我們往往便會取「TK」2碼(如圖所示)。 (錯) 但細想一下,便知「難」字的字首下方是個「夫」字,仍由「QO」2碼組成,所以,「難」字的字首應該是「TO」。 (對) 好了,現在再想想:「勤」字的字首是甚麼? 答案 (八)包含省略原則(特徵原則) 「包含省略」可以說是眾多取碼原則中,最難理解和最抽象的一個。「包含省略」本身的意思是:當字首或字身的最後一個字型,被另一個字型最少三面包住的時候,為求取碼方便,於是便取那外圍的一個字型,而不取那被包含在內的字型。 以「適」字舉例說,字首是「Y」,字身按著「1、2、尾」的取碼次序,理應取「YCR」,然而,由於「R」位於「B」的字型之內,我們便要取「B」而不取「R」,「適」字的倉頡碼亦因此變為「Y-YCB」。 「包含省略」這個原則有幾個缺點:第一,初學者很難介定怎樣才是三面包圍(或甚麼是三面包圍);第二,「包含省略」的原則「看來」有很多例外的情況,而且並不絕對正確。 讓我們先研究一下第二個問題,舉例說:「雨」這個字,倉頡碼是「MLBY」,「巫」這個字的倉頡碼是「MOO」;「雨」加上「口」,再加上「巫」便組成「靈」這個字。「雨」是字首,「口口口」是字身第一部份,「巫」是字身第二部份,按著「1、尾.1、尾.尾」的取碼原則,「靈」的倉頡碼應該是「MY-RR-O」,但由於「Y」被「B」包著、「O」被「M」包著,所以「靈」的倉頡碼便變成「MB-RR-M」。 看來並不困難,是不是?我們又為甚麼說「包含省略」並不絕對正確呢? 讓我們再看看「需」字:「雨」字倉頡碼為「MLBY」,「而」字的倉頡碼是「MBLL」,那麼「需」字的倉頡碼是什麼呢? 很多同學都會認為是「MB-MB」,那實在是被「包含省略」的原則和名稱所誤導。「包含省略」正確一點來說,應該稱為「包含取代」或「包含交換」,因為這個原則只可以「換碼」,絕不可以「省略」,以剛才的例子為例,「靈」字原為「MY-RR-O」,我們以「B」換取「Y」;以「M」換取「O」,因此,「靈」字的倉頡碼便變成「MB-RR-M」了。 「需」字的倉頡碼原為「MY-MBL」,字首「雨」字的「Y」字型被「B」字型包著;字身「而」字「L」字型亦被「B」字型包著,我們可以用「B」換「Y」,但我們不能以「B」換「L」,因為「B」早就存在了(原為MY-MBL嘛)。因此,「需」字的倉頡碼是「MB-MBL」。 假若我們在「需」字左邊加上「企人邊」,情況又不同了,「儒」字的倉頡碼原為「O-MY-L」,我們可以用「B」換「Y」;再用「B」換「L」,於是「儒」字的倉頡碼便變成「O-MB-B」了。 處理這個原則時,可試問自己以下幾個問題: 問題一:這個字是否「分體字」?(一般來說,只有「分體字」才有「包含取代」現象) 問題二:假若沒有「包含取代」原則,這個字的倉頡碼會是甚麼? 問題三:這個字的「字首」和「字身」最後一個字型(碼)有沒有被其他字型包圍著? 問題四:若有的話,可否進行取代? (九)部份省略(可以不理) 既說「連體字」取「頭、2、3、尾」,「分體字」取「頭、尾;頭、2、尾」,其餘不取的字型全都省略,不用輸入。 (十) 速成輸入法:只取一字頭尾兩碼,然後從清單中選擇所需要的字。 學「倉頡」等於學了「速成」,因為「速成輸入法」只取一個字的頭尾兩碼。 例: 倉頡碼 速成碼 我 HQIHI 你O-NFOF 他O-PDOD 為IKNFIF 「速成輸入法」看來比較易學,然而,由於這種輸入法太多重碼字,所以輸入速度比「倉頡」慢很多很多。另外,用慣了「速成」的人往往不再想學「倉頡」,所以,筆者建議各位盡量少用。 (「勤」字字首 答案:TM) ......倉頡取碼原則(綱要) .......例外字 ........練習
「包含省略」可以說是眾多取碼原則中,最難理解和最抽象的一個。「包含省略」本身的意思是:當字首或字身的最後一個字型,被另一個字型最少三面包住的時候,為求取碼方便,於是便取那外圍的一個字型,而不取那被包含在內的字型。 以「適」字舉例說,字首是「Y」,字身按著「1、2、尾」的取碼次序,理應取「YCR」,然而,由於「R」位於「B」的字型之內,我們便要取「B」而不取「R」,「適」字的倉頡碼亦因此變為「Y-YCB」。 「包含省略」這個原則有幾個缺點:第一,初學者很難介定怎樣才是三面包圍(或甚麼是三面包圍);第二,「包含省略」的原則「看來」有很多例外的情況,而且並不絕對正確。 讓我們先研究一下第二個問題,舉例說:「雨」這個字,倉頡碼是「MLBY」,「巫」這個字的倉頡碼是「MOO」;「雨」加上「口」,再加上「巫」便組成「靈」這個字。「雨」是字首,「口口口」是字身第一部份,「巫」是字身第二部份,按著「1、尾.1、尾.尾」的取碼原則,「靈」的倉頡碼應該是「MY-RR-O」,但由於「Y」被「B」包著、「O」被「M」包著,所以「靈」的倉頡碼便變成「MB-RR-M」。 看來並不困難,是不是?我們又為甚麼說「包含省略」並不絕對正確呢? 讓我們再看看「需」字:「雨」字倉頡碼為「MLBY」,「而」字的倉頡碼是「MBLL」,那麼「需」字的倉頡碼是什麼呢? 很多同學都會認為是「MB-MB」,那實在是被「包含省略」的原則和名稱所誤導。「包含省略」正確一點來說,應該稱為「包含取代」或「包含交換」,因為這個原則只可以「換碼」,絕不可以「省略」,以剛才的例子為例,「靈」字原為「MY-RR-O」,我們以「B」換取「Y」;以「M」換取「O」,因此,「靈」字的倉頡碼便變成「MB-RR-M」了。 「需」字的倉頡碼原為「MY-MBL」,字首「雨」字的「Y」字型被「B」字型包著;字身「而」字「L」字型亦被「B」字型包著,我們可以用「B」換「Y」,但我們不能以「B」換「L」,因為「B」早就存在了(原為MY-MBL嘛)。因此,「需」字的倉頡碼是「MB-MBL」。 假若我們在「需」字左邊加上「企人邊」,情況又不同了,「儒」字的倉頡碼原為「O-MY-L」,我們可以用「B」換「Y」;再用「B」換「L」,於是「儒」字的倉頡碼便變成「O-MB-B」了。 處理這個原則時,可試問自己以下幾個問題: 問題一:這個字是否「分體字」?(一般來說,只有「分體字」才有「包含取代」現象) 問題二:假若沒有「包含取代」原則,這個字的倉頡碼會是甚麼? 問題三:這個字的「字首」和「字身」最後一個字型(碼)有沒有被其他字型包圍著? 問題四:若有的話,可否進行取代?


















 無法分割
無法分割















 (對)
(對) (錯)取「J」不及取「Q」多
(錯)取「J」不及取「Q」多 (錯)不精簡,共4個碼。
(錯)不精簡,共4個碼。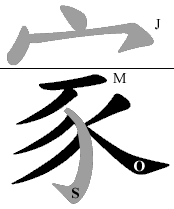


 (錯)
(錯) (對)
(對)